


เห็นได้ชัดว่าการรับรู้ของมนุษย์และอุปกรณ์อิเล็กทรอนิกส์เช่นคอมพิวเตอร์นั้นแตกต่างกัน มนุษย์สามารถเข้าใจอะไรก็ได้ผ่านภาษาธรรมชาติ แต่คอมพิวเตอร์ก็ไม่เข้าใจ คอมพิวเตอร์ต้องการนักแปลเพื่อแปลงภาษาที่เขียนในรูปแบบที่มนุษย์อ่านได้ไปเป็นรูปแบบที่คอมพิวเตอร์อ่านได้
คอมไพเลอร์และล่ามเป็นประเภทของนักแปลภาษา ตัวแปลภาษาคืออะไร คำถามนี้อาจเกิดขึ้นในใจของคุณ
ตัวแปลภาษาเป็นซอฟต์แวร์ที่แปลโปรแกรมจากภาษาต้นฉบับที่อยู่ในรูปแบบที่มนุษย์สามารถอ่านได้เป็นโปรแกรมที่เทียบเท่าในภาษาวัตถุ โดยทั่วไปภาษาต้นฉบับนั้นเป็นภาษาการเขียนโปรแกรมระดับสูงและโดยทั่วไปภาษาวัตถุจะเป็นภาษาเครื่องของคอมพิวเตอร์จริง
แผนภูมิเปรียบเทียบ
| พื้นฐานสำหรับการเปรียบเทียบ | ผู้รวบรวม | ล่าม |
|---|---|---|
| อินพุต | มันต้องใช้โปรแกรมทั้งหมดในเวลา | ต้องใช้รหัสหรือคำสั่งทีละบรรทัด |
| เอาท์พุต | มันสร้างรหัสวัตถุกลาง | มันไม่ได้สร้างรหัสวัตถุกลางใด ๆ |
| กลไกการทำงาน | การรวบรวมจะทำก่อนที่จะดำเนินการ | การรวบรวมและการดำเนินการเกิดขึ้นพร้อมกัน |
| ความเร็ว | ค่อนข้างเร็วกว่า | ช้าลง |
| หน่วยความจำ | ความต้องการหน่วยความจำเพิ่มขึ้นเนื่องจากการสร้างรหัสวัตถุ | ต้องการหน่วยความจำน้อยลงเนื่องจากไม่ได้สร้างรหัสวัตถุระดับกลาง |
| ข้อผิดพลาด | แสดงข้อผิดพลาดทั้งหมดหลังจากการรวบรวมทั้งหมดในเวลาเดียวกัน | แสดงข้อผิดพลาดของแต่ละบรรทัดทีละหนึ่ง |
| ตรวจจับข้อผิดพลาด | ยาก | เปรียบเทียบได้ง่ายกว่า |
| การเขียนโปรแกรมภาษาที่เกี่ยวข้อง | C, C ++, C #, Scala, typescript ใช้คอมไพเลอร์ | Java, PHP, Perl, Python, Ruby ใช้ล่าม |
ความหมายของคอมไพเลอร์
คอมไพเลอร์เป็นโปรแกรมที่อ่านโปรแกรมที่เขียนด้วยภาษาระดับสูงและแปลงเป็นเครื่องหรือภาษาระดับต่ำและรายงานข้อผิดพลาดในโปรแกรม มันจะแปลงซอร์สโค้ดทั้งหมดในครั้งเดียวหรืออาจใช้เวลาหลายครั้งในการทำเช่นนั้น แต่ในที่สุดผู้ใช้จะได้รับรหัสที่คอมไพล์ซึ่งพร้อมที่จะดำเนินการ

คอมไพเลอร์ทำงานบนเฟส ขั้นตอนต่าง ๆ สามารถแบ่งออกเป็นสองส่วนคือ:
- ขั้นตอนการวิเคราะห์ ของคอมไพเลอร์ยังเรียกว่าส่วนหน้าซึ่งโปรแกรมจะถูกแบ่งออกเป็นส่วนที่เป็นส่วนประกอบพื้นฐานและตรวจสอบไวยากรณ์ความหมายและไวยากรณ์ของรหัสหลังจากที่สร้างรหัสกลาง ขั้นตอนการวิเคราะห์รวมถึงการวิเคราะห์คำศัพท์วิเคราะห์ความหมายและการวิเคราะห์ไวยากรณ์
- ขั้นตอนการสังเคราะห์ คอมไพเลอร์ยังเป็นที่รู้จักกันในนามแบ็คเอนด์ที่รหัสกลางถูกปรับให้เหมาะสมและสร้างรหัสเป้าหมาย ขั้นตอนการสังเคราะห์รวมถึงการเพิ่มประสิทธิภาพรหัสและตัวสร้างรหัส
เฟสของคอมไพเลอร์
ตอนนี้มาทำความเข้าใจการทำงานของแต่ละขั้นตอนอย่างละเอียด
- ตัววิเคราะห์คำย่อ : มันสแกนรหัสเป็นกระแสของตัวละครจัดกลุ่มลำดับของตัวอักษรเป็นคำย่อและส่งออกลำดับของโทเค็นที่มีการอ้างอิงถึงภาษาการเขียนโปรแกรม
- ตัววิเคราะห์ไวยากรณ์ : ในขั้นตอนนี้โทเค็นที่สร้างขึ้นในขั้นตอนก่อนหน้านี้จะถูกตรวจสอบกับไวยากรณ์ของภาษาการเขียนโปรแกรมไม่ว่านิพจน์นั้นจะถูกต้องทางไวยากรณ์หรือไม่ มันทำให้ต้นไม้แยกวิเคราะห์สำหรับการทำเช่นนั้น
- Semantic Analyzer : ตรวจสอบว่านิพจน์และคำสั่งที่สร้างขึ้นในเฟสก่อนหน้าเป็นไปตามกฎของภาษาการเขียนโปรแกรมหรือไม่และจะสร้างทรีการแยกวิเคราะห์ที่มีคำอธิบายประกอบ
- ตัวสร้างรหัสระดับกลาง : มันสร้างรหัสระดับกลางที่เทียบเท่าของรหัสต้นฉบับ มีตัวแทนจำนวนมากของรหัสกลาง แต่ TAC (รหัสที่อยู่สาม) เป็นที่ใช้กันอย่างแพร่หลายมากที่สุด
- เครื่องมือเพิ่มประสิทธิภาพโค้ด : ปรับปรุงความต้องการด้านเวลาและพื้นที่ของโปรแกรม สำหรับการทำเช่นนั้นมันจะกำจัดรหัสซ้ำซ้อนที่มีอยู่ในโปรแกรม
- ตัวสร้างโค้ด : นี่คือขั้นตอนสุดท้ายของคอมไพเลอร์ซึ่งโค้ดเป้าหมายสำหรับเครื่องนั้นถูกสร้างขึ้น จะดำเนินการเช่นการจัดการหน่วยความจำการลงทะเบียนที่ได้รับมอบหมายและการปรับแต่งเฉพาะเครื่อง
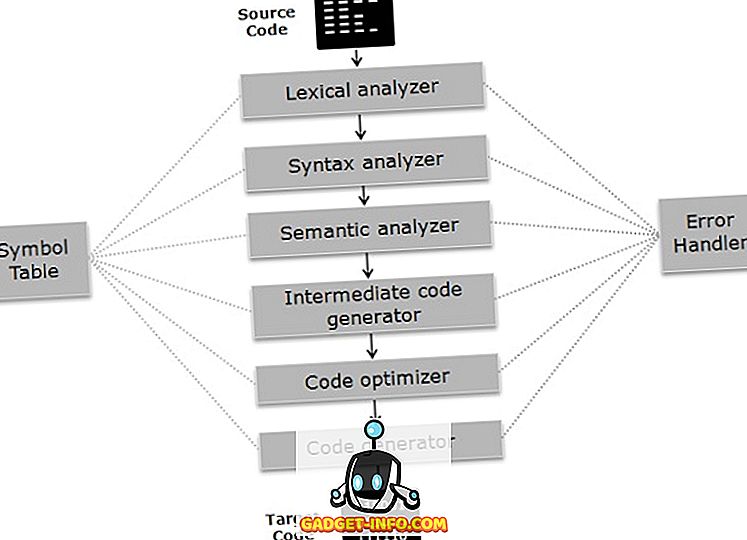
ตารางสัญลักษณ์ เป็นโครงสร้างข้อมูลที่จัดการตัวระบุพร้อมกับชนิดข้อมูลที่เกี่ยวข้องที่เก็บอยู่ ตัวจัดการข้อผิดพลาด ตรวจจับรายงานแก้ไขข้อผิดพลาดที่พบระหว่างเฟสต่างๆของคอมไพเลอร์
คำจำกัดความของล่าม
ล่ามเป็นอีกทางเลือกหนึ่งสำหรับการใช้ภาษาการเขียนโปรแกรมและทำงานเหมือนกับตัวแปลภาษา ล่ามดำเนินการ lexing, การ แยกวิเคราะห์ และการ ตรวจสอบประเภท คล้ายกับคอมไพเลอร์ แต่ล่ามจะประมวลผลแผนผังต้นไม้โดยตรงเพื่อเข้าถึงนิพจน์และดำเนินการคำสั่งแทนที่จะสร้างรหัสจากต้นไม้ไวยากรณ์
ล่ามอาจต้องการการประมวลผลทรีไวยากรณ์เดียวกันมากกว่าหนึ่งครั้งนั่นคือเหตุผลที่การตีความช้ากว่าการดำเนินการโปรแกรมที่คอมไพล์
การรวบรวมและการตีความอาจรวมกันเพื่อใช้ภาษาโปรแกรม ซึ่งคอมไพเลอร์สร้างรหัสระดับกลางจากนั้นรหัสจะถูกตีความมากกว่ารวบรวมเป็นรหัสเครื่อง
การใช้ล่ามนั้นมีประโยชน์ในระหว่างการพัฒนาโปรแกรมซึ่งส่วนที่สำคัญที่สุดคือสามารถทดสอบการปรับเปลี่ยนโปรแกรมได้อย่างรวดเร็วแทนที่จะรันโปรแกรมอย่างมีประสิทธิภาพ
ความแตกต่างที่สำคัญระหว่างคอมไพเลอร์และล่าม
เรามาดูความแตกต่างที่สำคัญระหว่างคอมไพเลอร์และล่าม
- คอมไพเลอร์ใช้โปรแกรมทั้งหมดและแปลมัน แต่ล่ามแปลคำสั่งโปรแกรมโดยคำสั่ง
- รหัสกลางหรือรหัสเป้าหมายถูกสร้างขึ้นในกรณีของคอมไพเลอร์ เทียบกับล่ามไม่ได้สร้างรหัสกลาง
- คอมไพเลอร์เปรียบเทียบได้เร็วกว่า Interpreter เนื่องจากคอมไพเลอร์ใช้โปรแกรมทั้งหมดในครั้งเดียวในขณะที่ล่ามจะคอมไพล์โค้ดแต่ละบรรทัดหลังจากที่อื่น
- คอมไพเลอร์ต้องการหน่วยความจำมากกว่าล่ามเนื่องจากการสร้างรหัสวัตถุ
- คอมไพเลอร์นำเสนอข้อผิดพลาดทั้งหมดพร้อมกันและเป็นการยากที่จะตรวจสอบข้อผิดพลาดในทางตรงกันข้ามล่ามแสดงข้อผิดพลาดของแต่ละคำสั่งทีละคนและมันง่ายต่อการตรวจสอบข้อผิดพลาด
- ในคอมไพเลอร์เมื่อเกิดข้อผิดพลาดในโปรแกรมมันจะหยุดการแปลและหลังจากลบข้อผิดพลาดทั้งโปรแกรมจะถูกแปลอีกครั้ง ในทางตรงกันข้ามเมื่อเกิดข้อผิดพลาดในล่ามจะป้องกันการแปลและหลังจากลบข้อผิดพลาดการแปลจะดำเนินการต่อ
- ในคอมไพเลอร์กระบวนการต้องใช้สองขั้นตอนซึ่งซอร์สโค้ดแรกถูกแปลเป็นโปรแกรมเป้าหมายจากนั้นเรียกใช้งาน ในขณะที่ล่ามมันเป็นกระบวนการหนึ่งขั้นตอนที่ซอร์สโค้ดรวบรวมและดำเนินการในเวลาเดียวกัน
- คอมไพเลอร์ใช้ในการเขียนโปรแกรมภาษาเช่น C, C ++, C #, Scala และอื่น ๆ ใน Interpreter อื่น ๆ ใช้ในภาษาเช่น Java, PHP, Ruby, Python เป็นต้น
ข้อสรุป
คอมไพเลอร์และล่ามมีวัตถุประสงค์เพื่อทำงานเดียวกัน แต่แตกต่างกันในขั้นตอนการดำเนินงานคอมไพเลอร์ใช้ซอร์สโค้ดในลักษณะรวมขณะที่ล่ามใช้ส่วนที่เป็นส่วนประกอบของซอร์สโค้ดคือคำสั่งโดยคำสั่ง
แม้ว่าทั้งคอมไพเลอร์และล่ามมีข้อดีและข้อเสียบางอย่างเช่นภาษาที่แปลความหมายถือเป็นข้ามแพลตฟอร์มคือรหัสเป็นแบบพกพา นอกจากนี้ยังไม่จำเป็นต้องรวบรวมคำสั่งก่อนหน้าซึ่งแตกต่างจากคอมไพเลอร์ซึ่งประหยัดเวลา ภาษาที่รวบรวมได้เร็วขึ้นเกี่ยวกับกระบวนการรวบรวม






